本文最后更新于:2021年4月15日 晚上
论文阅读方面:
[1] Chefer H, Gur S, Wolf L. Transformer Interpretability Beyond Attention Visualization[J]. arXiv preprint arXiv:2012.09838, 2020.
[2] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision. Springer, Cham, 2020: 213-229.
[3] Wang Y, Xu Z, Wang X, et al. End-to-End Video Instance Segmentation with Transformers[J]. arXiv preprint arXiv:2011.14503, 2020.
代码执行方面:
本周对[1]这篇文章的代码进行了复现,在我们的ImageNet VIDs数据集上进行了测试,效果如下:
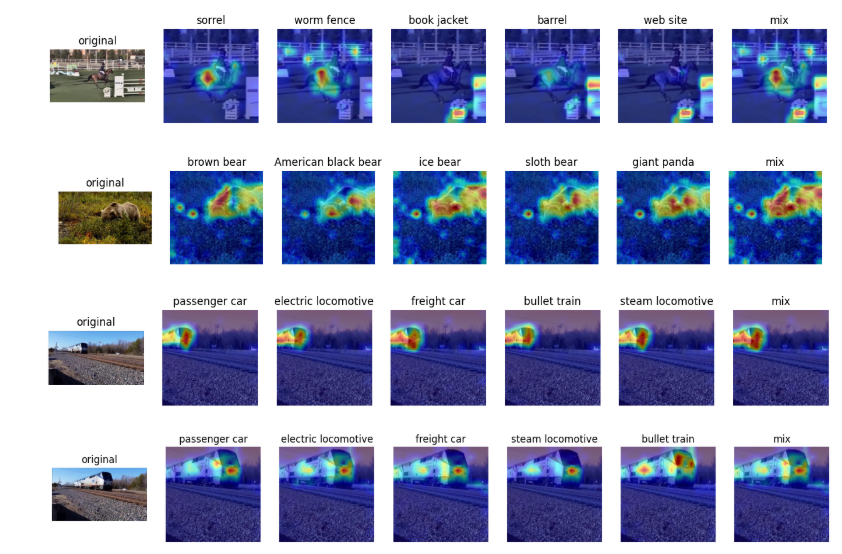
其中,第一列是原图,第2-6列是模型预测出的得分最高的前5类的Heatmap,最后一列是我加的,是对前5列图像的融合。为什么要做融合呢?是因为该方法对于目标的分类过于详细,光熊就分为了棕熊、美国黑熊、北极熊等等…在我们的数据集中并没有分的这么详细,进行融合就可以保证最终提取出感兴趣区域的效果。
自己的想法:
- 未来考虑如何将本方法应用于视频目标检测中去,比如对原始特征图用该热图进行增强?这是目前的初步想法,未来计划做实验进行验证。
1.Transformer Interpretability Beyond Attention Visualization
简介
自注意力机制,特别是Transformer逐渐成为文本处理领域的主流,并且在CV领域流行起来。为了可视化图像中有助于分类的部分,现有方法依赖于所获取到的注意力图,或者沿着注意力图进行启发式传播。本文提出了一种新的方法来为Transformer计算相关性。该方法基于深度泰勒分解规则分配局部相关性,之后传播这些相关性。该传播包含注意力层和跳跃连接。作者的解决方案基于一个特定的公式,该公式显示了跨层保持总体相关性。
Transformer网络的主要构成是自注意力层,其在两个tokens之间分配一个成对的注意力值。
本文提出的可视化方法:

总结:
- 本文提出了一种基于Transformer的方法将有助于分类的部分进行可视化。
- 其效果相对之前的方法有很大提高,并且是开源的,可以考虑将该方法用于VID
2.End-to-end object detection with transformers
简介
作者将目标检测框看为一个直接的集合预测问题,简化了检测的pipeline,有效的移除了需要手动设置的内容,如非极大值抑制、anchor生成,这些内容包含了我们对于任务的先验知识。作者提出的新框架的主要成分是DETR,其是一个基于集合的全局loss,强制通过双向匹配统一的进行预测,并且是一个Transformer Encoder-decoder结构。给出一个固定的所学习到的目标queries的小集合,DETR可以推出目标的关系、全局图像上下文,来直接并行输出最终的预测结果集合。
DETR模型
在检测中直接进行集合预测有两个因素必不可少:1.一个集合预测Loss,强制其在预测和GT box之间唯一匹配。2.一个预测一组目标并对其关系建模的结构。

DETR使用CNN作为backbone来学习输入图像的特征,之后将其压平,与positional encoding合并后送入Transformer的编码器。解码器以object queries以及编码器的输出作为输入。最后将解码器的输出送入一个共享的前向传播网络(FFN)来预测边界框的类别和位置。
总结:
- 本文最大的创新点是摒弃了原有的CNN网络,使用Transformer做目标检测。
- 文中提到该方法可适用于任何深度学习框架,并且核心代码仅有几百行(Pytorch)。
- 缺点是对小目标的检测效果不尽如人意,还有继续优化的空间。
3. End-to-End Video Instance Segmentation with Transformers
简介:
视频实例分割(VIS)需要同时对视频中的实例进行进行分类、分割、跟踪。本文在Transformer之上提出了一个新的视频实例分割框架:VisTR,其将VIS任务看作一个直接的端到端并行序列解码/预测问题。其核心是一个高效的实例序列匹配和分割策略,它作为一个整体在序列级别上监督和分段实例。VisTR对实例分割进行帧化处理,并在相同的相似性学习视角进行跟踪,因此简化了pipeline,与现有方法有很大不同。
本质上,实例分割和实例跟踪都与相似性学习有关:实例分割学习像素级别的相似性,实例跟踪学习多个实例之间的相似性。于是很自然的想法是:在单个框架内解决这两个子任务,其还可以相互促进。
VisTR
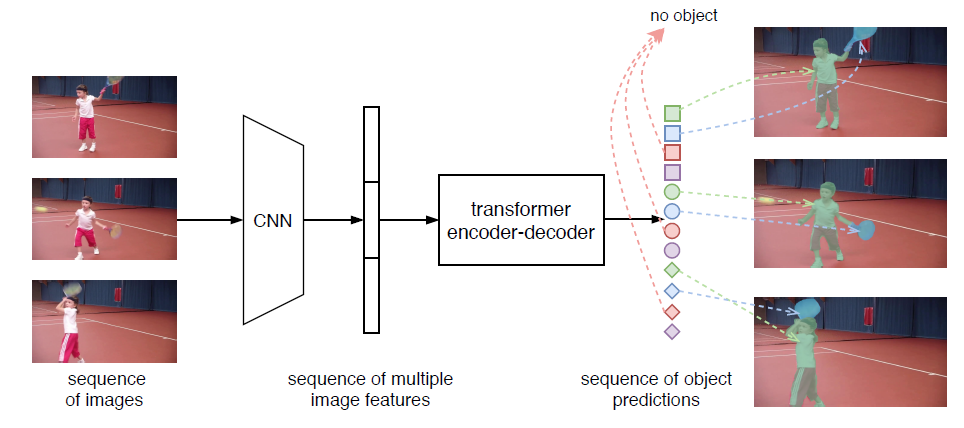
整体结构如图所示,首先使用标准的CNN模块独立的提取每一帧的特征,之后按照顺序串联图像特征形成clip-level特征序列。第二步,将clip-level的特征序列输入Transformer,输出一个有序的目标预测序列。
图中相同的形状表示相同图像的预测结果,相同的颜色代表不同图像的相同实例。预测序列的顺序与输入图像的顺序相同,并且每一帧内的实例预测顺序也相同。因此,视力跟踪在实例分割的框架中被无缝的、自然的实现。
为了实现上述目标,有两个主要挑战:
- 如何维持输出的顺序。
- 如何从Transformer网络的输出获得每个实例mask序列。
作者针对这两个问题,分别提出了instance sequence matching 策略、instance sequence segmentation模块。
instance sequence matching 策略在输出实例序列 和GT实例序列之间,执行双向的图匹配,从宏观上监督顺序。Instance sequence segmentation通过自注意力为每个实例跨多帧积累mask特征,并且通过3D卷积对每个实例的mask序列进行分割。作者展示了位置信息对于VIS密集预测任务的重要性,并且分析了实例查询嵌入在不同级别的影响。
原始Transformer是auto-regressive(自回归)的,一个一个的生成token。为了效率,作者采用了一个非自回归的Transformer变体,来实现并行序列生成。
总结:
创新点:
- 基于Transformer提出了一个新的视频实例分割框架VisTR,将VIS任务看做一个直接的端到端的平行序列解码/预测问题。
- VisTR从一个全新的相似性学习的视角解决VIS问题。在一个相同的框架内实现了分割和跟踪。
- VisTR提出了两个新的策略:instance sequence matching & segmentation。这两个策略使得可在整个序列级别上监督和分割实例。