本文最后更新于:2021年4月14日 晚上
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. arXiv preprint arXiv:1706.03762, 2017.
[2] Han L, Wang P, Yin Z, et al. Exploiting Better Feature Aggregation for Video Object Detection[C]//Proceedings of the 28th ACM International Conference on Multimedia. 2020: 1469-1477.
[3] Chen Q, Wang Y, Yang T, et al. You Only Look One-level Feature[J]. arXiv preprint arXiv:2103.09460, 2021.
[4] Chefer H, Gur S, Wolf L. Transformer Interpretability Beyond Attention Visualization[J]. arXiv preprint arXiv:2012.09838, 2020.
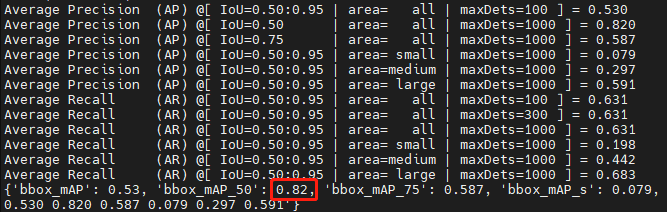
本周对香港中文大学mmlab开源的SELSA代码进行了环境配置、初步运行测试。在不调整原始参数的情况下,其mAP可以达到82%,比原始论文中报告的80.25%高出不少。
下一步计划认真研读这份代码,在其基础上进行改进。
1.Attention is all you need
- 这篇文章是目前很火的Transformer框架的开山之作,遂找来进行阅读。
摘要
主流的顺序翻译模型基于复杂的循环或卷积神经网络,其包含编码器和解码器。效果最好的模型通过注意力机制连接编码器和解码器。本文提出了一个新的简单的网络结构,Transformer,仅仅基于注意力机制,完全抛开循环和卷积。
递归模型通常沿着输入输出序列的符号位置进行因子计算。这种固有的顺序性排除了训练示例中的并行化,当序列长度变长时,并行化就变得至关重要,因为内存约束限制了示例之间的批处理。
本文提出的Transformer模型结构,避开了循环,完全依赖注意力机制来庙会输入和输出之间的全局依赖。
背景
自注意力(内部注意力)是一个注意力机制,联系不同位置的单个序列,来计算序列的一个表示。自注意力已经在多种任务上成功应用,包括阅读理解,抽象总结等。
端到端的memory网络基于递归注意力机制,而不是序列对其的递归,并且已经被证明在简单语言问答和语言建模任务中表现良好。
Transformer是第一个完全依赖自注意力来计算输入和输出表示的转移模型,而无需使用序列对齐的RNN或卷积。
模型结构
最有竞争力的神经序列转移模型具有一个编码-解码结构。这里的编码器将符号表示的输入序列(x1…xn)映射为连续表示的序列z=(z1,…zn)。给出z,解码器生成一个输出序列(y1,…ym)每次表示一个元素。在每一步模型是自动回归的。生成下一个时,将先前生成的符号用作附加输入。
Transformer遵循以上的整体结构,使用堆叠的self-attention和point-wise、编码器使用全连接层。

3.1 编码器和解码器的堆叠
编码器
编码器由N=6个完全相同的层堆叠组成。每一层有两个子层。首先是一个multi-head 自注意力机制,其次是一个简单的position-wise的全连接前向传播网络。在这两个子层中采用了残差连接、层正规化。每个子层的输出是
,其中$Sublayer(x)$是sub-layer自身的函数。为了促进残差连接,模型中所有的子层和嵌入层的输出维度都是512维。
解码器
解码器也由N=6个完全相同的层堆叠而成。除了每个编码器层中的两个子层之外,解码器插入了第三个子层,该第三个子层在编码器堆栈的输出上执行multi-head attention。与编码器相同,解码器也在每个子层中采用了残差连接、层正规化。作者也修改了解码器堆栈中的self-attention子层,以防止器出现在后续的位置。这种掩盖,以及输出嵌入被一个位置偏移的事实,确保了对位置i的预测只能依赖于小于i位置的已知输出。
3.2 Attention
注意力函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。将输出计算为值的加权和,其中分配给每个值的权重是通过查询与相应键的兼容性函数来计算的。

总结
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
编码器的输入句子首先会经过一个自注意力层,可以帮助编码器再对每个单词编码时关注输入句子的其他单词。
自注意力层的输出会传递到前馈神经网络中,每个位置单词对应的前馈神经网络都完全一样。
解码器中也有编码器的自注意力层和前馈层。此外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分。
2.Exploiting Better Feature Aggregation for Video Object Detection
- 这篇文章是目前视频目标检测论文中报告精度最高的一篇,mAP达到84.8%。
作者指出了当前基于关系的特征聚合方法存在的三个问题:
- 只考虑目标间的时间依赖,忽略了空间关系
- 这些方法在时间阈上直接聚合支持帧所有的proposal,不考虑其是否属于同一类。使得其不可避免的从不相关的类中带来有缺陷的proposals。
- 其直接聚合支持proposal和目标proposal的特征,没有进行特征对齐。为后续的分类和回归带来了没有经过对齐的特征。
基于以上问题,本文提出了以下创新:
- 提出Class-constrained spatial-temporal relation network
- 操作目标region proposals,学习两种关系:
- 从辅助帧采样的相同类的region proposal依赖
- 目标帧不同目标proposal之间的空间关系
- 首次同时编码时域和空域的信息。
- 操作目标region proposals,学习两种关系:
- 提出Correlation-based feature alignment module,更好的在时域进行特征聚合。
- 提出了一个基于相关的特征对齐方法,在时域上对齐支持帧和目标帧,以进行特征聚合。
- 提出class homogeneity constraint,将视频帧顺序打乱,通过在RPN后加入一个分类器,来实现仅用相同类的proposal来增强目标proposal,减少特征聚合中有缺陷的region proposals,并且滤除来自其他类的无效的信息,得到更精确的聚合特征。这样不仅大大减少了需要计算相关性的proposal的数量,并且是在一个统一的端到端的网络框架中,不需要后处理(隐含的嵌入了传统的后处理策略)。
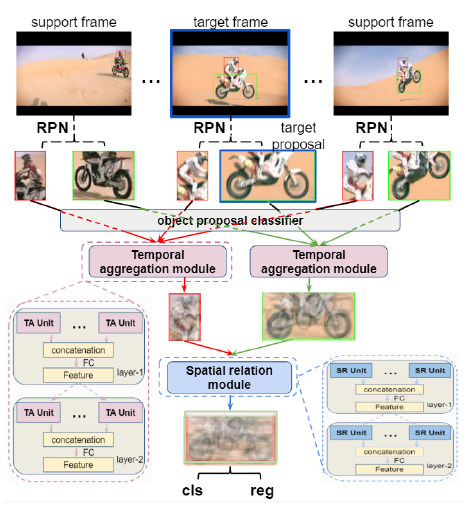
首先使用RPN获得每一帧的proposal。之后设计一个简单的分类器来预测每个proposal的类名。之后使用时间聚合模块(TAM)用支持帧的同类proposal特征来增强目标proposal特征。特征对齐模块(TA)被插入到时间聚合模块中,以进行更好地特征聚合。最终,使用空间关系模块(SRM),分析相同帧目标的交互,来对目标的拓补关系建模,进一步使用相同帧的proposal来增强目标proposal的特征。
所提出的模块:
TAM模块:用于将辅助帧的同类proposal特征来增强目标proposal,其中采用Transformer机制来选出可用于特征聚合的最具信息量的辅助proposal。通过cos相似性计算出目标proposal和辅助proposal的表观相似性。之后使用计算出的相似性对特征进行加权和。最后使用Liner Projection,重新将原始的表观特征包含在内。
SRM模块:挖掘目标帧中proposal之间的空间位置关系,计算出几何相似性。最终的相似性又包含了上一步计算出的表观相似性。
特征对齐模块:通过利用标准差和均值,计算出支持proposal(x,y)位置和目标proposal(m,n)位置的相关性(其中包含了1x1的卷积、对目标proposal的(m,n)位置进行复制、用提出的公式执行“相关”操作)。最终根据计算出的相关性权重,对支持proposal特征图进行加权和,就可以得到其在目标proposal(m,n)位置的对齐过的特征。
总结:
作者提出了一个class-constrained时空关系网络和一基于相关的特征对齐模块。前者同时考虑了不同帧相同类的时间依赖性、以及同一帧不同目标的空间拓补关系。此外,作者将辅助帧打乱(随机采样),利用了整个视频的目标信息,相比传统的后处理方法更有效。
3. You Only Look One-level Feature
本文指出FPN(特征金字塔网络)的成功之处在于其“分而治之”的解决思路而非多尺度特征融合。作者从优化的角度出发,仅使用一级特征进行检测,提出了YOLOF(You Only Look One-level Feature)。YOLOF有两个关键性模块:Dilated Encoder与Uniform Matching。
YOLOF框架
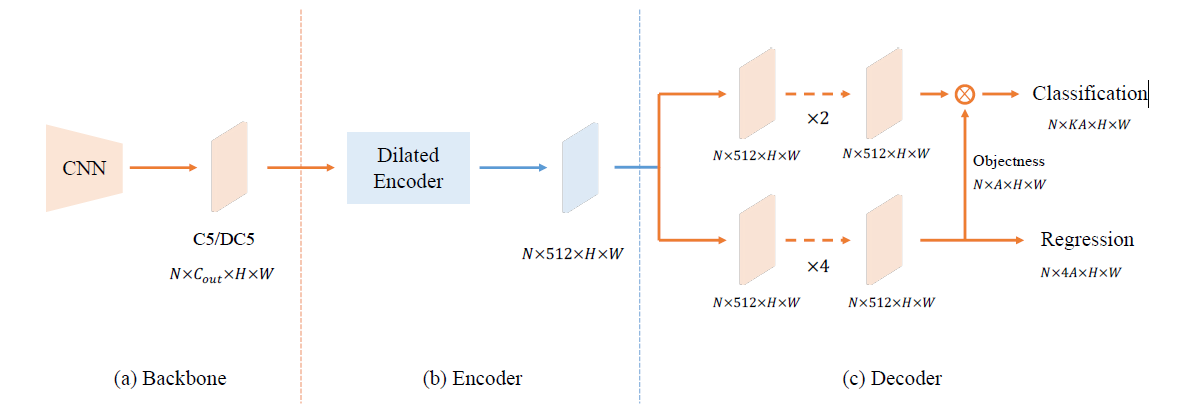
- BackBone。在所有模型中,作者简单的采用了ResNet与ResNeXt作为骨干网络,所有模型在ImageNet上训练,输出C5特征该通道数为2048,下采样倍率为32;
- Encoder。作者参考FPN添加了两个投影层,将通道数降到512,并堆叠四个不同扩张因子的残差模块;
- Decoder。在这部分,作者采用了RetinaNet的主要设计思路,它包含两个并行的任务相关的Head分别用于分类和回归。作者仅仅添加两个微小改动:(1) 参考DETR中的FFN设计让两个Head的卷积数量不同,回归Head包含4个卷积而分类Head则仅包含两个卷积;(2) 作者参考AutoAssign在回归Head上对每个锚点添加了一个隐式目标预测。
- Other Detail。正如前面所提到的YOLOF中的预定义锚点是稀疏的,这会导致目标框与锚点之间的匹配质量下降。作者在图像上添加了一个随机移动操作以缓解该问题,同时作者发现这种移动对于最终的分类是有帮助的。
总结:
创新点:
- FPN的关键在于针对稠密目标检测优化问题的“分而治之”解决思路,而非多尺度特征融合
- 提出了一种简单而有效的无FPN的baseline模型YOLOF,其包含两个关键成分
- Dilated Encoder:用于增加感受野,覆盖所有的目标尺度。
- Uniform Matching :解决Positive Anchor的不平衡问题。
4. Transformer Interpretability Beyond Attention Visualization
摘要
自注意力机制,特别是Transformer逐渐成为文本处理领域的主流,并且在CV领域流行起来。为了可视化图像中有助于分类的部分,现有方法依赖于所获取到的注意力图,或者沿着注意力图进行启发式传播。本文提出了一种新的方法来为Transformer计算相关性。该方法基于深度泰勒分解规则分配局部相关性,之后传播这些相关性。该传播包含注意力层和跳跃连接。作者的解决方案基于一个特定的公式,该公式显示了跨层保持总体相关性。
Transformer网络的主要构成是自注意力层,其在两个tokens之间分配一个成对的注意力值。
本文提出的可视化方法:

总结:
- 本文提出了一种基于Transformer的方法将有助于分类的部分进行可视化。
- 其效果相对之前的方法有很大提高,并且是开源的,可以考虑将该方法用于VID。