本文最后更新于:2021年3月20日 晚上
最近一周阅读了2篇视频目标检测方向的论文,1篇特征提取的论文。
阅读文献:
[1] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[2] Jiang Z, Liu Y, Yang C, et al. Learning where to focus for efficient video object detection[C]//European Conference on Computer Vision. Springer, Cham, 2020: 18-34.
[3] Shvets M, Liu W, Berg A C. Leveraging long-range temporal relationships between proposals for video object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 9756-9764.
1.FPN
主要解决了目标检测而在处理多尺度变化问题时的不足。提出特征金字塔网络结构,能在极少增加计算量的情况下,处理目标检测的多尺度变化问题。

识别尺寸差异大的目标现有方法:
a)通过图像金字塔来构建不同尺度的特征金字塔
- 优点:对不同尺度的图像进行特征提取,能产生多尺度特征表示,所有等级特征图都具有较强语义信息,甚至包括一些高分辨率的特征图。
- 缺点:
- 推理时间长,内存占用大
b)利用单个高层特征图
Faster-RCNN中的RPN层就是利用单个高层特征图进行目标分类和bbox回归。
c)金字塔形特征层级
SSD为了避免使用低层特征图,放弃使用已经计算的层,从网络的高层开始构建金字塔(在VGG网络的conv4之后,再添加几个新的卷积层)。因此SSD错过了重用高分辨率特征图的机会,没有充分利用到低层特征图中的空间信息(这些信息对于检测小目标非常重要)。
d)特征金字塔
FPN是一种具有侧向连接的自上而下的网络结构,用来构建不同尺寸的具有高级语义信息的才特征图。
能够在较少增加计算量的前提下融合低分辨率但语义信息较强的特征图(高层) 和 高分辨率但语义信息较弱的空间信息丰富的特征图。
FPN网络

(1)Bottom-up pathway
前馈Backbone的一部分,每一级往上用step=2降采样。输出尺寸相同的叫做一级(stage),选择每一级的最后一层特征图经过1x1卷积后作为逐元素相加的参考。
(2)Top-down pathway and lateral connections
自顶向下的过程通过“上采样”(up-sampling)将顶层的小特征图放大到与上一级的特征图一样的大小。
上采样的方法是最近邻插值法:
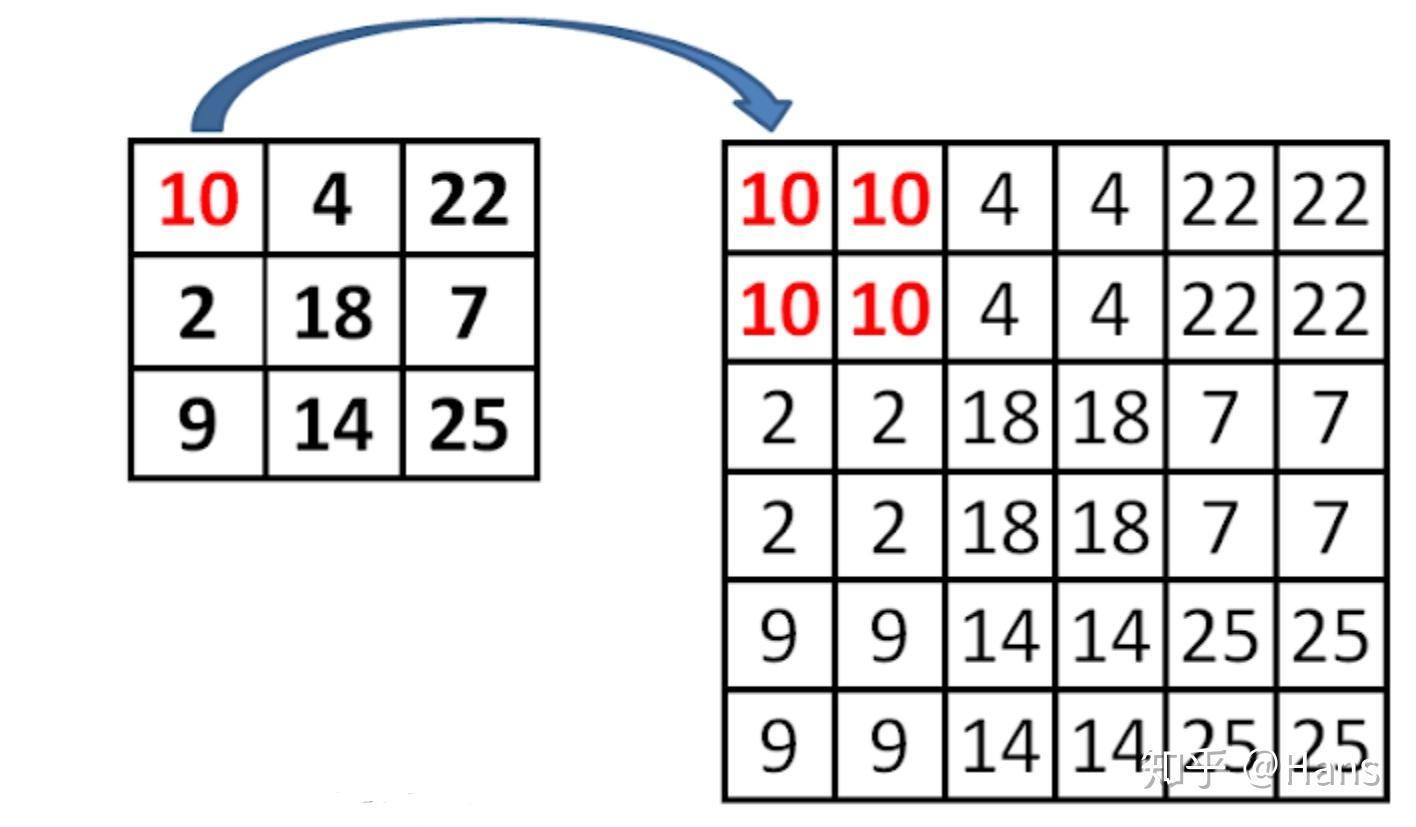
对于使用最近邻插值法的个人思考:使用最近邻值插值法,可以在上采样的过程中最大程度地保留特征图的语义信息(有利于分类),从而与bottom-up 过程中相应的具有丰富的空间信息(高分辨率,有利于定位)的特征图进行融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图。
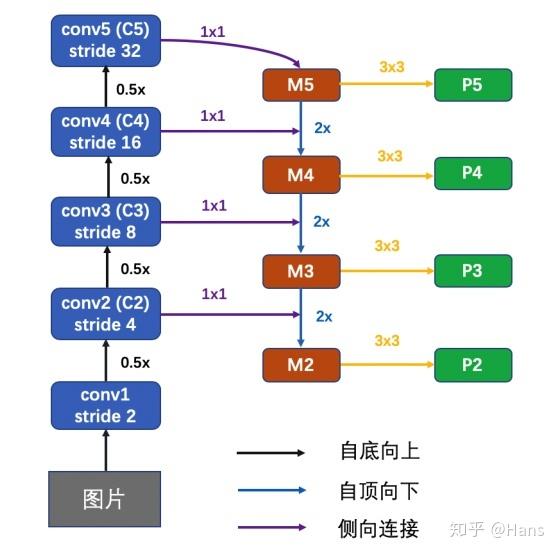
具体过程为:C5层先经过1 x 1卷积,改变特征图的通道数(文章中设置d=256,与Faster R-CNN中RPN层的维数相同便于分类与回归)。M5通过上采样,再加上(特征图中每一个相同位置元素直接相加)C4经过1 x 1卷积后的特征图,得到M4。这个过程再做两次,分别得到M3,M2。M层特征图再经过3 x 3卷积(减轻最近邻近插值带来的混叠影响,周围的数都相同),得到最终的P2,P3,P4,P5层特征。
另外,和传统的图像金字塔方式一样,所有M层的通道数都设计成一样的,本文都用d=256。
FPN应用于RPN层
Faster RCNN中的RPN是通过最后一层的特征来做的。最后一层的特征经过3x3卷积,得到256个channel的卷积层,再分别经过两个1x1卷积得到类别得分和边框回归结果。这里将特征层之后的RPN子网络称之为网络头部(network head)。对于特征层上的每一个点,作者用anchor的方式预设了9个框。这些框本身包含不同的尺度和不同的长款比例。
FPN针对RPN的改进是将网络头部应用到每一个P层。由于每个P层相对于原始图片具有不同的尺度信息,因此作者将原始RPN中的尺度信息分离,让每个P层只处理单一的尺度信息。具体的,对{32^2、64^2、128^2、256^2、512^2}这五种尺度的anchor,分别对应到{P2、P3、P4、P5、P6}这五个特征层上。每个特征层都处理1:1、1:2、2:1三种长宽比例的候选框。P6是专门为了RPN网络而设计的,用来处理512大小的候选框。它由P5经过下采样得到。
另外,上述5个网络头部的参数是共享的。作者通过实验发现,网络头部参数共享和不共享两种设置得到的结果几乎没有差别。这说明不同层级之间的特征有相似的语义层次。这和特征金字塔网络的原理一致。
2.LSTS
主要贡献:
1.提出LSTS来传播跨帧的高级特征,其可以精确的计算时空对应。LSTS(Learnable Spatio-Temporal Sampling)可以精确的的学习相邻帧特征之间的语义级别的对应。采样位置首先被随机初始化,然后在检测监督的指导下迭代更新,以找到更好地空间对应。 LSTS将采样位置的偏移看作参数,在bbox和类别监督的指导下,通过反向传播来学习最优的偏移量。
2.提出了SRFU(Sparsely Recursive Feature Updating)模块,对时间关系建模,加速密集的低级特征。
3.提出了DFA(Dense Feature Aggregation)模块,增强逐帧特征,增强非关键帧特征表示。
之前利用时间信息的方法可被分为两类:
1.利用时间信息进行后处理,保证目标检测结果的一致性。这些方法通常使用图像检测器来获得检测结果,然后通过box-level的匹配(如跟踪器或现成的光流),对结果进行联合。基于后处理的方法速度较慢。
2.利用特征表示的时间信息,主要通过聚合相邻帧的特征来提升检测精度,或者传播特征来避免密集的特征提取,以提升速度。
当在帧间传播特征时,基于光流的扭曲方法有一些缺点:
1.光流大量增加了模型的参数量,使得对嵌入式设备的应用不友好。
2.光流不能准确地表示高级特征之间的对应关系。由于网络的感受野增加,高级语义特征的微小漂移,总是对应图像级别的大运动。
3.光流提取耗费时间。
为了解决上述问题,LSTS模块被提出来传播帧间的高级特征。该模块可以在整个数据集上学习其自身的跨帧空间对应。此外,没有额外的光流,也显著加速了传播过程。
给出两帧It和It+k,及提取出的特征Ft和Ft+k,LSTS模块将首先采样特定的位置,然后计算采样到的位置在特征图Ft和Ft+k上的相似性。最终,采样位置将在最后的检测监督的指导下被迭代更新,这使得我们可以更精确的传播和对齐跨帧的高级特征。
对比基于光流扭曲的特征传播方法,所提出的方法更轻量级,可以在特征级别精确的建模跨帧对应。
方法:
为了将低计算复杂度,对关键帧使用大的特征提取器H,对非关键帧使用轻量级的特征提取器L。为了利用帧间的关系,一个memory feature Fmemory在关键帧上维持,其通过SRFU模块逐渐更新。此外,由于在非关键帧使用了轻量级的特征提取网络,非关键帧的低级特征不能包含好的检测结果。因此使用DFA模块来提升非关键帧的低级特征,通过在关键帧使用Fmemory。

为了简化,t0、t1(关键帧)将被喂给高级特征提取器H,t1+k(非关键帧)将被喂给低级特征提取器L。通过SRFU来捕捉时间信息,以维持Fmemory,Fmemory在关键帧迭代更新。与此同时,DFA传播关键帧的Fmemory来增强和丰富非关键帧的低级信息。LSTS被嵌入到SRFU和DFA中,来景区的传播和对齐跨帧特征。最终,SFRU和DFA的输出被未给任务网络来进行最终的预测。
LSTS

LSTS由4步组成:1)在特征图Ft上随机采样一些位置。2)通过相似性对比计算亲和力权重。相关相似性权重通过嵌入的特征f(Ft)和g(Ft+k)计算,f和g是嵌入的函数,旨在减少特征Ft和Ft+k的通道数,节约计算花费。3)特征Ft和计算出的权重一起被合并为一个被传播的特征F‘t+k。4)在训练期间位置通过反向传播迭代更新。训练后,最终学习到的采样位置将被用于推理。
黄色方格表示第t+k帧特定的网格位置,蓝色方格表示第t帧采样的相关位置。
在给出特征图Ft,Ft+k之后,LSTS允许我们计算对应的相似性权重。
采样
为了精确的将特征从Ft传播到Ft+k,我们需要两帧之间精确的空间对应。首先在邻域内初始化一些采样位置,提供了粗相关。通过学习LSTS可以转换和缩放采样位置的分布,逐渐建立一个精确的空间对应。
对比
有了对应的位置,就可以计算其相似性。为了减少计算开销,Ft和Ft+k被嵌入化为f(Ft)和g(Ft+k)。然后,基于嵌入化的特征f(Ft)和g(Ft+k)计算对应的相似性权重。
聚合
计算出第t帧的pn位置与第t+k帧p0位置相似性权重后,即可估计第t+k帧p0位置的值。

更新
为了学习对应的ground truth分布,在训练期间采样位置pn通过反向传播更新(根据最终检测loss)。

在训练之后,最终学习到的采样位置可被用于在推理过程中传播和对齐帧间特征。LSTA是SRFU和DFA的核心。

图4:SRFU和DFA的结构,+是聚合单元。Transform由一些卷积组成,用于提升非关键帧的低级特征。对于SRFU,使用LSTS模块传播最后一个关键帧特征Fmemoryt0到当前关键帧Fmemoryt1 。而对于DFA,使用LSTS模块将关键帧特征Fmemoryt1传播到非关键帧t1+k,来提升特征质量,获得更好地检测结果。
SRFU
SRFU模块允许利用内在的时间线索内的视频传播和聚集稀疏关键帧在整个视频的高层特征。具体来说,SRFU模块在整个视频上维护和递归更新一个Fmemory。在图4的过程中,直接使用新的关键帧特征Ft1更新memory feature是次优的,因为t0和t1之间存在运动偏差。因此,使用LSTS模块,估计运动,生成一个对齐的特征Ft1 align。之后,使用一个聚合单元来生成更新过的特征Ft1 memory和关键帧的task特征(用于检测和定位)。
DFA
考虑到计算复杂性,作者在非关键帧使用轻量级的特征提取网络,将会提取到低级特征。因此DFA模块可以重用密集的关键帧的高级特征来提升非关键帧的质量。具体来说,如图4b所示,非关键帧特征Flowt1+k先被喂给一个Transform单元(计算量很小),预测一个语义级别的特征Fhight1+k。由于第t1帧和t1+k帧之间存在运动偏差,将LSTS模块用于Ft1 memory来生成一个对齐的特征Ft1+k align。之后使用一个聚合单元来生成非关键帧上的task特征Ft1+k task。相比于低级特征Flowt1+k,Ftaskt1+k包含更多语义级别的信息,允许我们获得更好地检测结果。
3.LLTR
简介
本文对单帧检测器进行了轻量化修改,可以解决视频中任意长的依赖性。显著提升了单帧检测器的精度,计算开销可以忽略不计。本文方法的新颖之处是:在目标proposal上操作的时间关系模块,其学习不同帧之间proposal的相似性,从之前或(和)之后帧选择proposal来支持当前帧的proposal。
本文的方法基于聚合视频相关部分的特征,以便就推定的检测是否正确做出更好的决策。这涉及确定视频的哪些部分与潜在检测相关,这些部分的特征的加权平均以及对那些更新的新特征的最终检测决策。考虑FPN中的region proposal作为潜在的检测和视频潜在的关系部分。也可以使用快速、高召回率的单步检测器的输出。无论如何,考虑长期时间关系的一个重大挑战是存在许多可能性。本文方法的一个关键方面是:将哪些proposal应该支持检测的问题分解,合并结果。
作者展示了如何使用关系模块来建模帧间对目标proposal的依赖,并且引入直接监督来学习表观关系。此外,证明了我们的方法从聚合长程时间关系中收益,当尝试考虑相隔1秒以上的帧时,用于竞争的模块效果会下降。这些优点来自于基于表观特征学习到了哪些proposal可能与潜在的检测相关,忽略了位置和时间上的差异。
主要贡献:
- 提出了一个新奇的proposal-level的时间关系块,来学习表观相似性,使用支持帧的特征来丰富目标帧的特征。
- 提出了一个使用时间关系模块来从视频中多个支持帧合并长程依赖的方法。
- online推理、速度与单帧baseline检测器相当
- 在学习过程中增加图监督
pixel-level的特征,如D&T、FGFA、STSN,随着时间快速退化。本文采用细粒度的instance-level的表观特征,不随时间退化,并且故意忽略的实例的空间位置,来释放更大的时间跨度的使用和跨多个时间跨度的聚集。我们的模块在每帧数百个proposal上运行,可以使用历史信息聚合特征,可以高效的端到端的反向传播信息至RPN和backbone网络。
Method
作者的目标是学习更新instance-level的特征,以在线方式更新检测器的预测,无需任何后处理步骤。为了实现这个目标,需要学习目标proposal间基于表观的关系。
基于表观的关系模块
假设在D维空间中,目标帧有N个proposal,支持帧有M个proposal。构建一个注意力机制来用支持帧特征的加权平均来更新目标帧的特征。

目标特征和支持特征首先使用一个linear层进行embedded。之后这两个矩阵经过特征归一化,这与以前的工作不同,在先前的工作中,外观关系被构建为嵌入特征的直接关联。我们注意到,如果不这样做,相关性主要由特征数量决定而不是由实际的关系决定。这在ROI-level的特征检测中非常重要,因为这些特征被认为是有偏差的并且具有较高的量级。第三步是构建表观关系矩阵G(图中的x),通过在所有目标特征对之间执行简单的相关。矩阵G被进一步用于在支持proposal上计算注意力权重,如果在视频中xi和xj与同一个实例相关,那么Gij的值就高,否则不相关的话,Gi,j的值就低。为了加强约束,给图G增加了一个监督损失。鼓励相同实例间的距离小,不同实例间的距离大。
在描述性外观关系矩阵G被构造之后,它被用作支持特征的注意机制中的权重。使用softmax对G进行归一化。可以想象,如果目标实例I具有来自j1、j2、.。。,jk的强support关系,然后Gij1,Gij2,.。。,Gijk的值高,只有这些值些会在softmax操作后“存活”。另一方面,如果i在支持帧中没有相应的proposal,那么第i行中的所有值都将是低的,并且softmax将不支持任何support实例,因此目标实例将接收不携带相关信号的简单平均support。
G^被用于聚合embedded支持特征,使用矩阵相乘层。在一个额外的linear层后,形成最终的聚合过的support特征矩阵,与输入的目标特征矩阵的大小相同,(最后一个线性层的输出维度仍然是D)。因此,使用逐元素相加来更新目标特征。
到目前为止,我们只讨论了如何根据support proposals更新目标特征。
Causal and Symmetric modes
为了给定的目标帧选择支持帧,我们引入了时间内核(temporal kernel)的概念。时间核是一个元组(K,s),表示大小和步距。大小K是关系推理中包含的帧数。因此,对于一个选定的目标帧,有k-1个支持帧。步幅s限制以s帧的统一时间间隔对K帧进行采样。
我们为给定的目标帧定义了两种核模式:Causal和Symmetric。在Causal模式下,支持帧仅从之前的帧中选取:t-s,t-2s,t-(K-1)s.在Symmetric模式下,支持帧从之前和之后选取:t-s,t+s。
Single model and Frozen Support Model settings
由于效率高,在单个模型中计算目标和支持特征是一个有吸引力的选择。在我们的单一模型设置中,目标和支持特征都是从同一层pool的ROI特征,并且网络是经过端到端训练的。这存在两个潜在的问题,首先,当核尺寸被设为K,训练时至少有K帧在一个设备上处理。若给定一个较大分辨率的图像用于检测,在标准的GPU存储器中只可能防止几张图像,因此,内核大小是有限的。第二,支持特征分布在检测器的训练期间是变化的,因为它是根据与目标特征相同的参数集计算的。
为了解决这些问题,我们引入了冻结支持模型设置,其中使用单帧预训练检测器(冻结支持模型)来提取实例级支持特征,同时主检测器一次运行单个图像,还接收固定支持特征作为附加输入。请注意,在训练期间,冻结支持模型不需要分配大的内存,因为不需要反向传播,这使得在训练期间可以使用更大的内核大小。在我们的实验部分,我们证明了事实上从同一个模型中学习这两个特性是有益的,并且我们在不同层次上的聚合降低了对大内核的需求。
训练和推理
正如第2节所讨论的,实例之间的几何关系被认为会随着时间而退化,即使使用了复杂的运动传播方法[1,3,26]。在我们的模型中,box之间的几何关系是有意不使用的,以便能够在推理过程中捕获长期依赖关系。我们证明了应用具有大时间步长s的核来捕捉长期关系的可能性。为此,我们训练一个关系模块,使其不可知于时间内核步长,这使得在推理过程中能够跨不同的时间步长进行聚合。
因此,对于训练和测试来说,核大小K作为模型的参数是固定的,但是时间步长是动态随机选择的。训练时,s选一次。请注意,由于上面提到的内存限制,模型是用单个s训练的,但是由于随机采样,关系模块在推理过程中是不可知的。这实现了多步聚合。在推理过程中,对几个不同的步长多次应用内核,并执行特征聚合。我们表明,延长时间跨步长(使用高达s = 256)不仅不会降低性能,而且显示了准确性的持续提高。
